I was recently working on a multi-vector dataset comparison in Deep Space. We had received Revit, Navisworks and tabular data, and I was comparing 3 different data drops of that information, particularly for changes in the quantities of specific types of elements. A ‘data drop’ is a set of data or files that you receive at a given point in time.
In the course of exporting the Navisworks data through to CSV, I came across a specific problem – the number of rows in imported CSV did not match the number of elements processed. Why?
As you may know, you can store line breaks inside parameters in Revit. There are very few good reasons to do this, but it still does happen. Once this happens, those line breaks need to be processed by tools down stream. I spent a lot of time in the early days of Deep Space figuring out how to ‘clean’ bad Revit data so we could still bring it into the platform for analysis. Usually, if the CSV writer or reader are smart enough, they should be able to deal with this problem. However, I discovered a bit of a gap in the available tools this time. What was the problem?
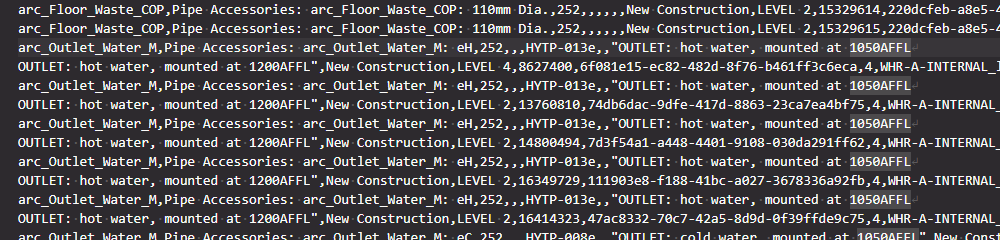
It turns out that the CSV was malformed, it was actually dirty or bad data. While it did have the line breaks, it did not consistently use double quotes to contain fields. So we had the situations where there would be line breaks that were inside the CSV fields or columns, but not inside double quotes. I tried a lot of different CSV readers, including Excel, LibreOffice, Google Sheets and PowerBI / PowerQuery, but they all tripped up at this data. Because they were using the rule ‘new line = new row of data’, the imported CSV information was coming in mangled.
How can we clean this data? We generally know there should be 17 fields or 16 commas per row of data. But we also know there can be line breaks inside fields… so it is a challenge to map a data row to CSV lines. In some cases 2 or 3 lines of CSV data might still just be one row of actual data.
After trying to use various out of the box solutions, I decided to build some Python code to try and solve this. I used Dynamo Sandbox 1.3 to do this, primarily out of habit, not because it is the best Python IDE out there 🙂 I ended up with a kind of line-merging iterator, here is some of the Python code below:
biglist = IN[0]
commact=[]
for ctr in range(len(biglist)):
astr=biglist[ctr]
strct=astr.count(',')
commact.append(strct)
counted=range(len(biglist))
fixedstr=[]
bad=[]
skips=[]
incr=0
for ctrx in range(len(biglist)):
if ctrx==skips:
pass
elif commact[ctrx]==16:
fixedstr.append(biglist[ctrx])
elif commact[ctrx]>16:
fixedstr.append(biglist[ctrx])
elif commact[ctrx]+commact[ctrx+1]==16:
jnr=[]
jns=biglist[ctrx]+biglist[ctrx+1]
fixedstr.append(jns)
skips=ctrx+1
else:
bad.append(ctrx)
OUT = bad, fixedstr, commact, counted
What does it do? Essentially, it counts the number of delimeters (commas) on one line, then it processes or merges lines based on that information.
This actually got me around 90% of the way there. Then I still had to do some manual fixes of things like ‘double double quotes’ that were also tripping up the CSV readers.
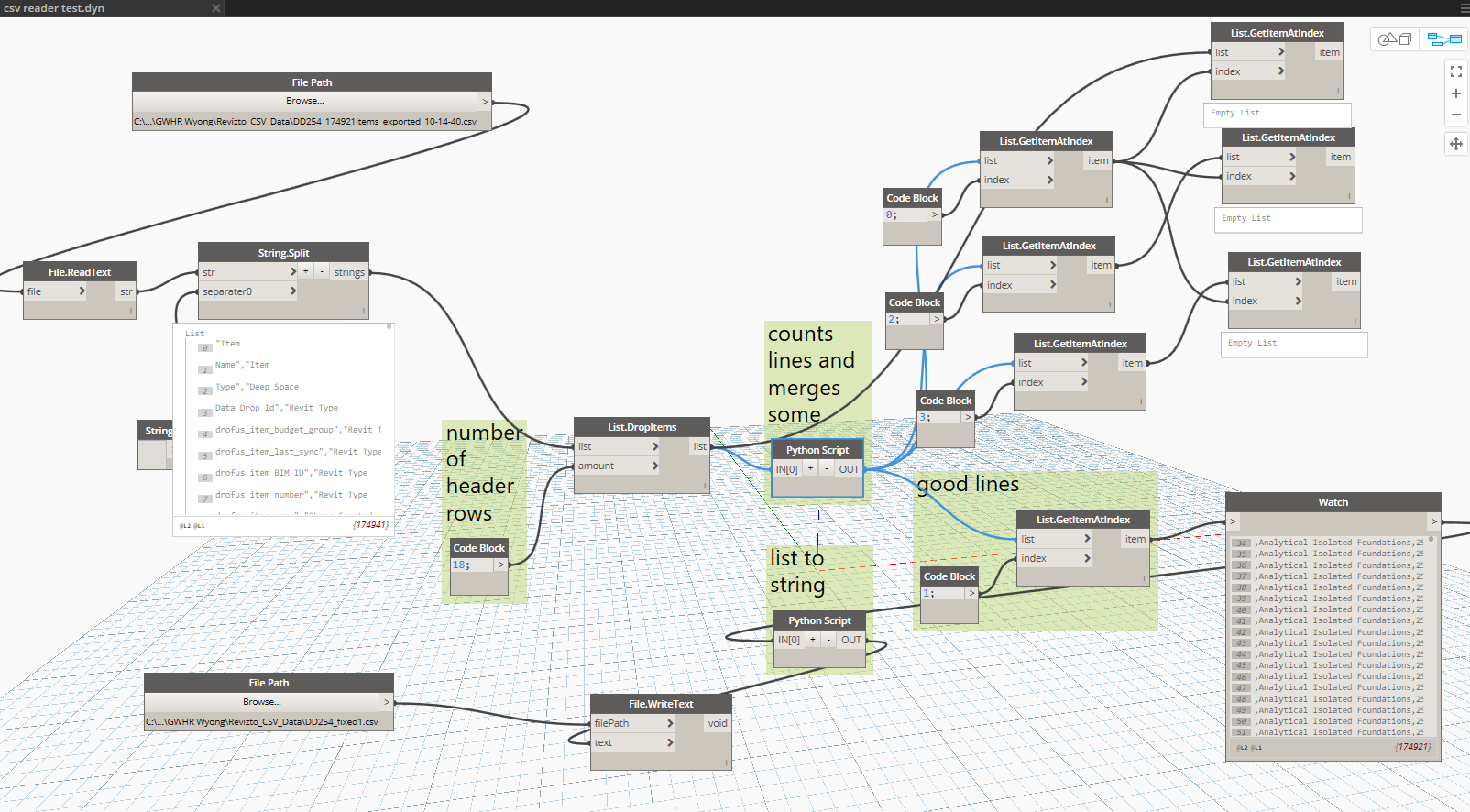
Above is a snapshot of the Dynamo script. And here is the script for download:
CSV Line Merge for Malformed CSV
What the the lessons here?
- Try and fix the source or native data if you can. Dealing with messy data downstream can be a real pain.
- If you need to solve this problem, you can pick up my code or work above and advance it a bit further to build a more robust ‘malformed CSV reader’
- Don’t let problems like this distract you during the holidays 🙂