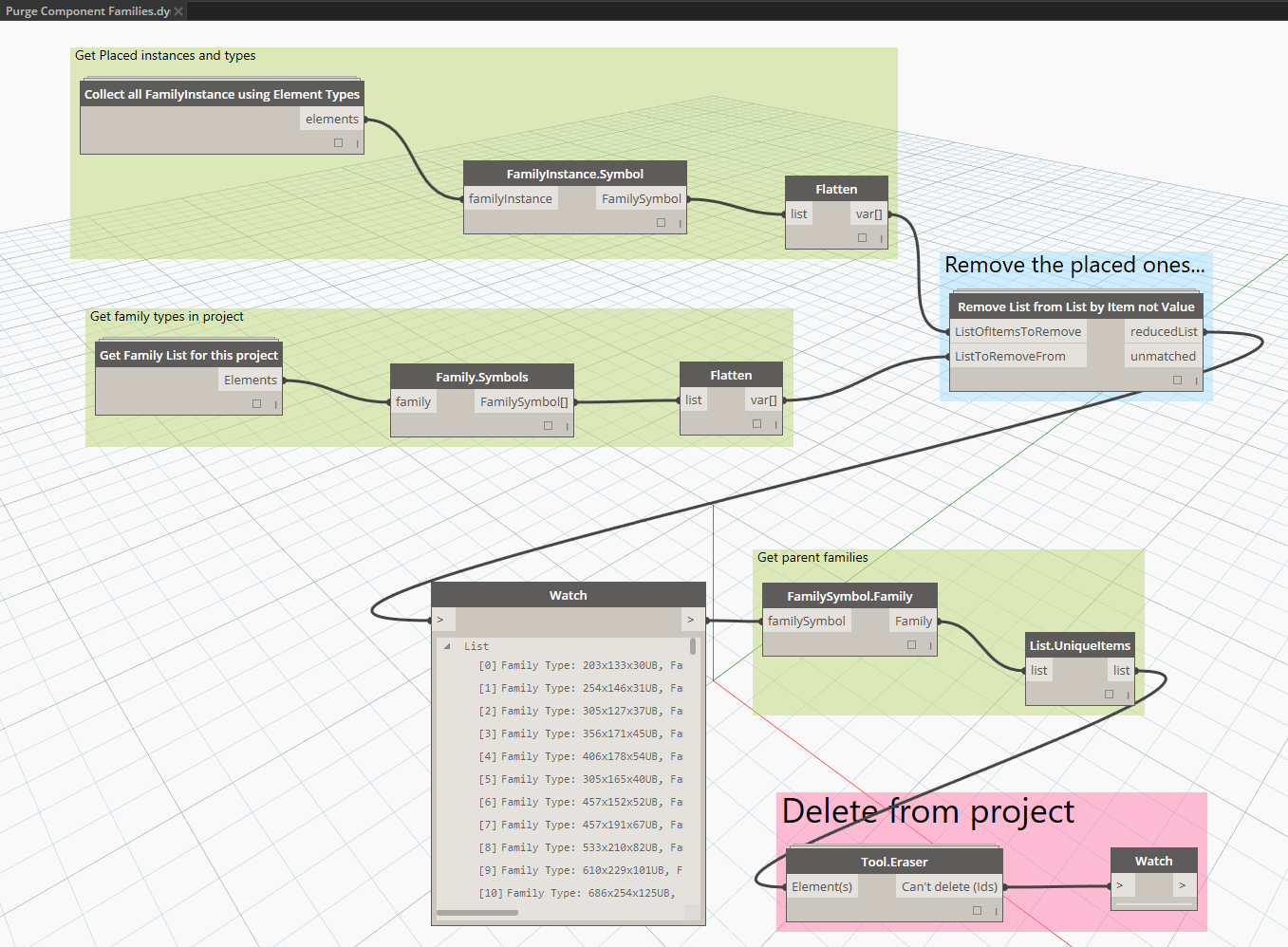
I saw a question like this on the forum so I had a quick go at it (see image below). Basically it checks what Family Types are placed against those loaded into the project, and then deletes unplaced componentFamiliesusing SteamNodes Tool.Eraser:
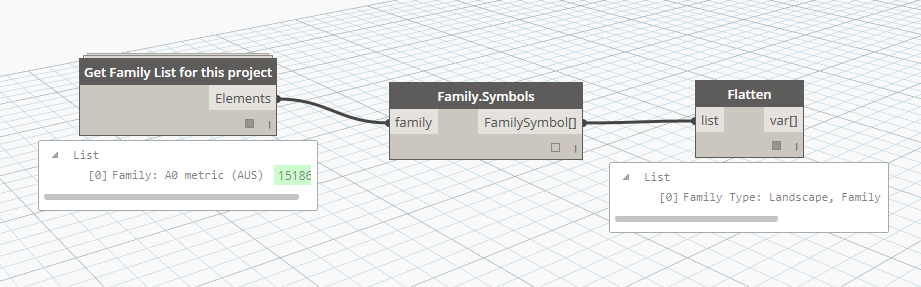
Post flight family list:
Future versions of this could start looking at system families / types using similar methodology.
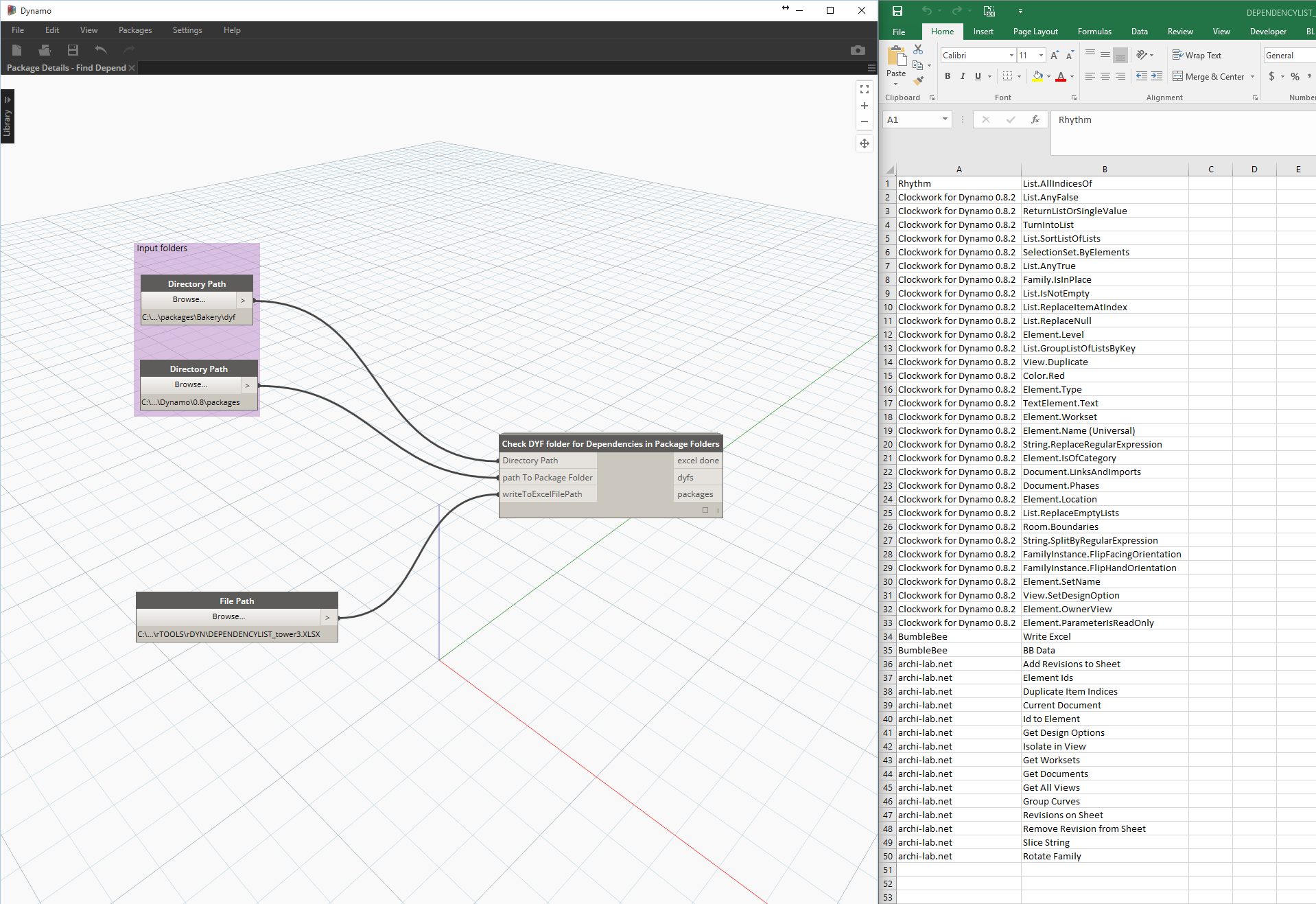
Every now and then, you may find that a package upgrade causes some ofyournodes to stop working. This may be because nodes have been removed from the package that you were using. You can use the two DYNs here to quickly check for missing dependencies:
Step 1
This will find dependencies from a selected package or definitions folder and export them to Excel:
Step 2
This will read the Excel file back in, and compare with node names in yourPackages folder (may take a while):
Both of these dyns can be run in standalone / sandbox mode.
If there are missing nodes, they should appear in the pink box. You could then go to DynamoPackages website, download previous version that had the dyf you want, and then copy the contents of that dyf into your own custom node.
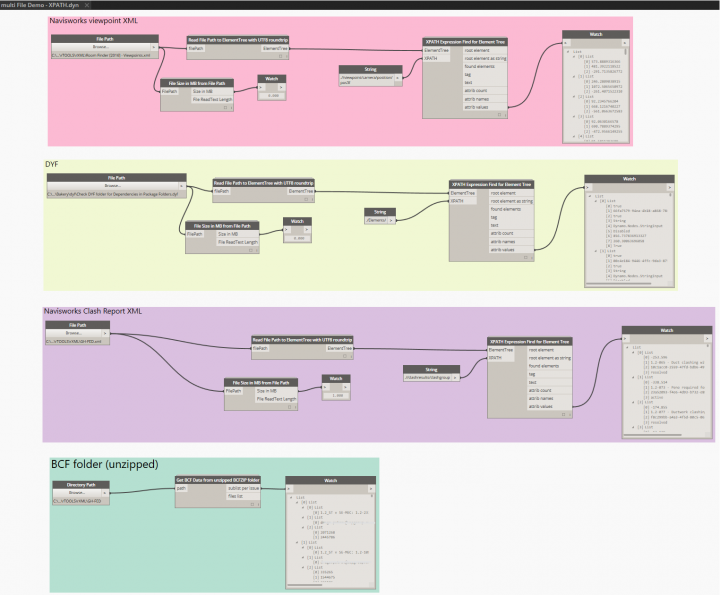
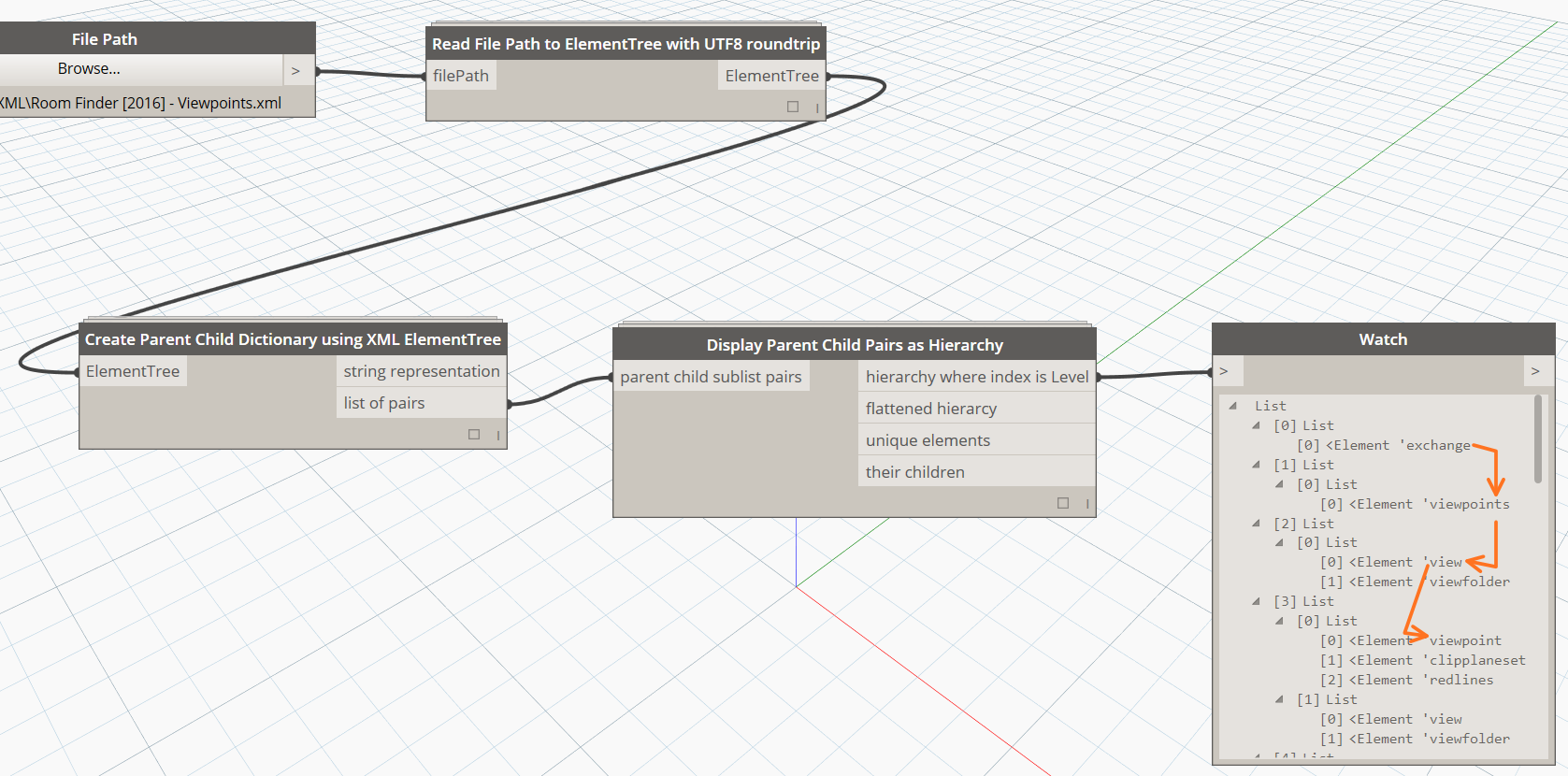
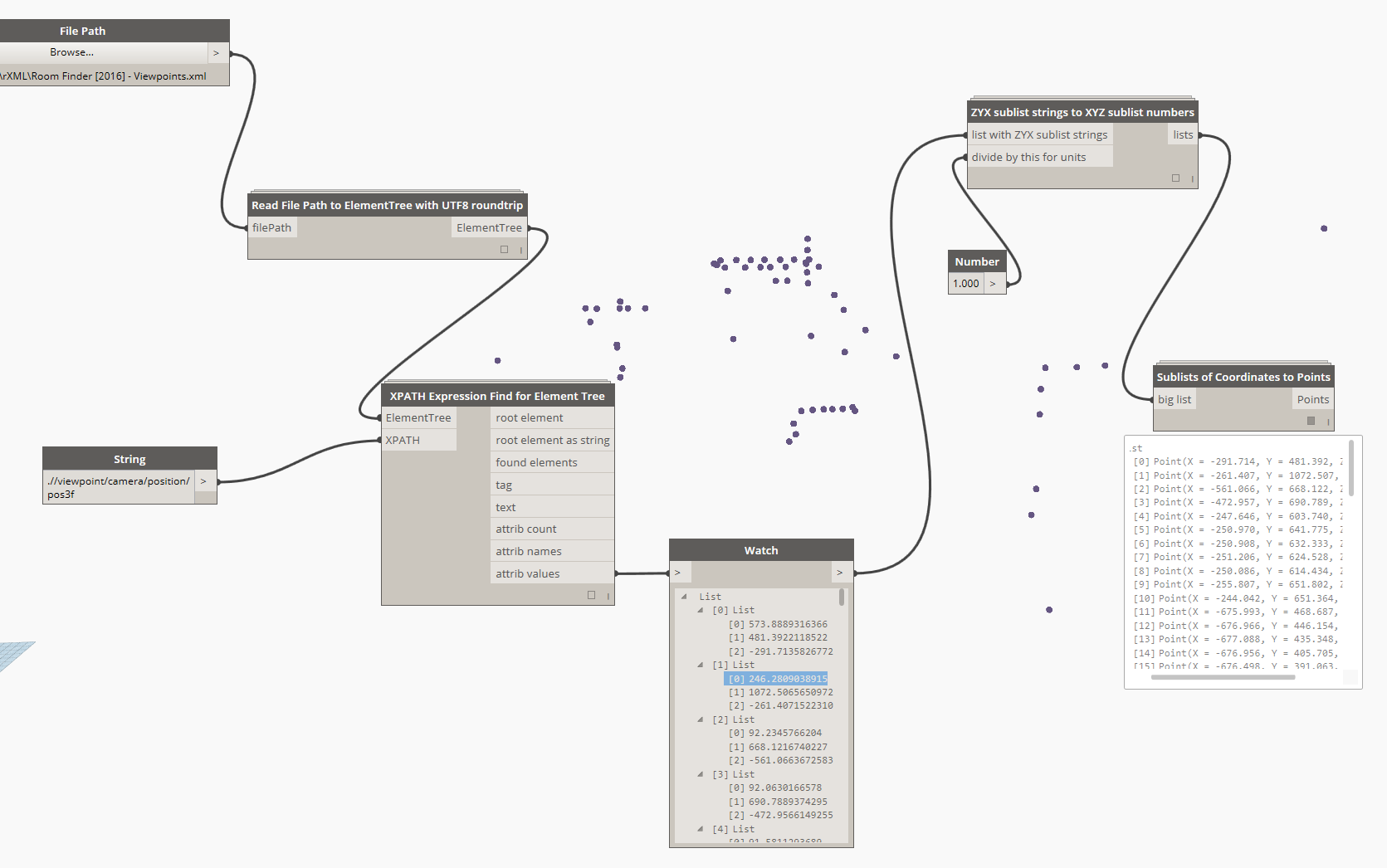
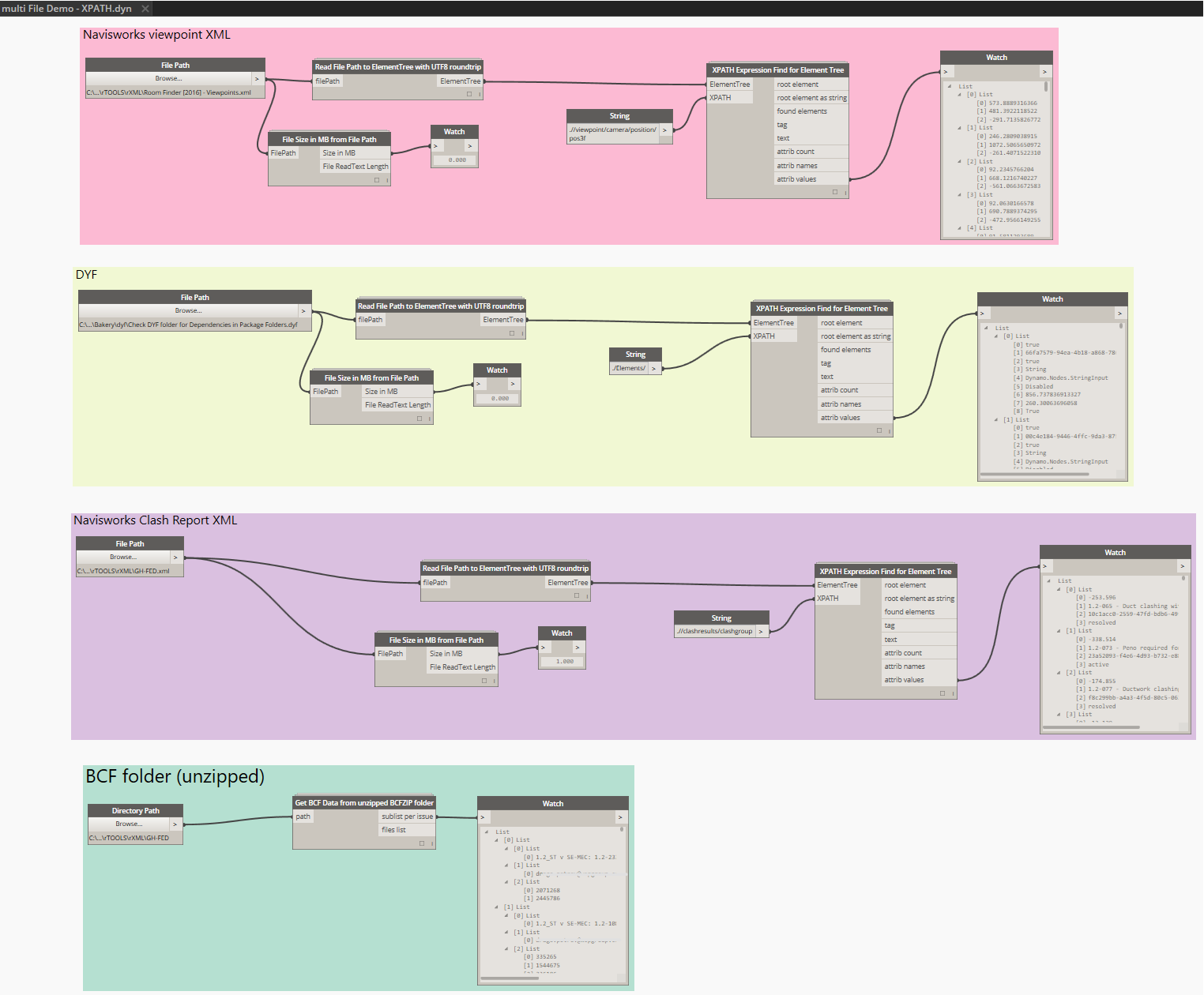
XMLfiles are everywhere. Andin the BIM world, we have to deal with a range of different xml file schemas, such as BCF, Navisworks Clash Reports and Viewpoints, and so forth. Hiding inside these XMLs there is some very useful information. For example, BCF files often have Element IDs in the viewpoint.bcfv component, and Navisworks XMLfiles often have point XYZ values. Can we easily get access to this information for usein Dynamo, and then inRevit?
Yes, we can! There were one or two ways to do this in Dynamo before, but here is my take on it…
Dynamo ships with IronPython, which in turn ships with an XML handler called ElementTree. I have created some basic nodes that give us access to ElementTree functions in Dynamo. Along the way, I learnt a bit about encoding and character sets. It turns out that Navisworks often inserts tricky characters into the XML (like the diameter symbol), so as a workaround (for now) I do a string encoding roundtrip to get rid of these problematic characters. In the same node, I create the ElementTree object: this is a special object that essentially represents structured information about the XML data. The initial import looks like this:
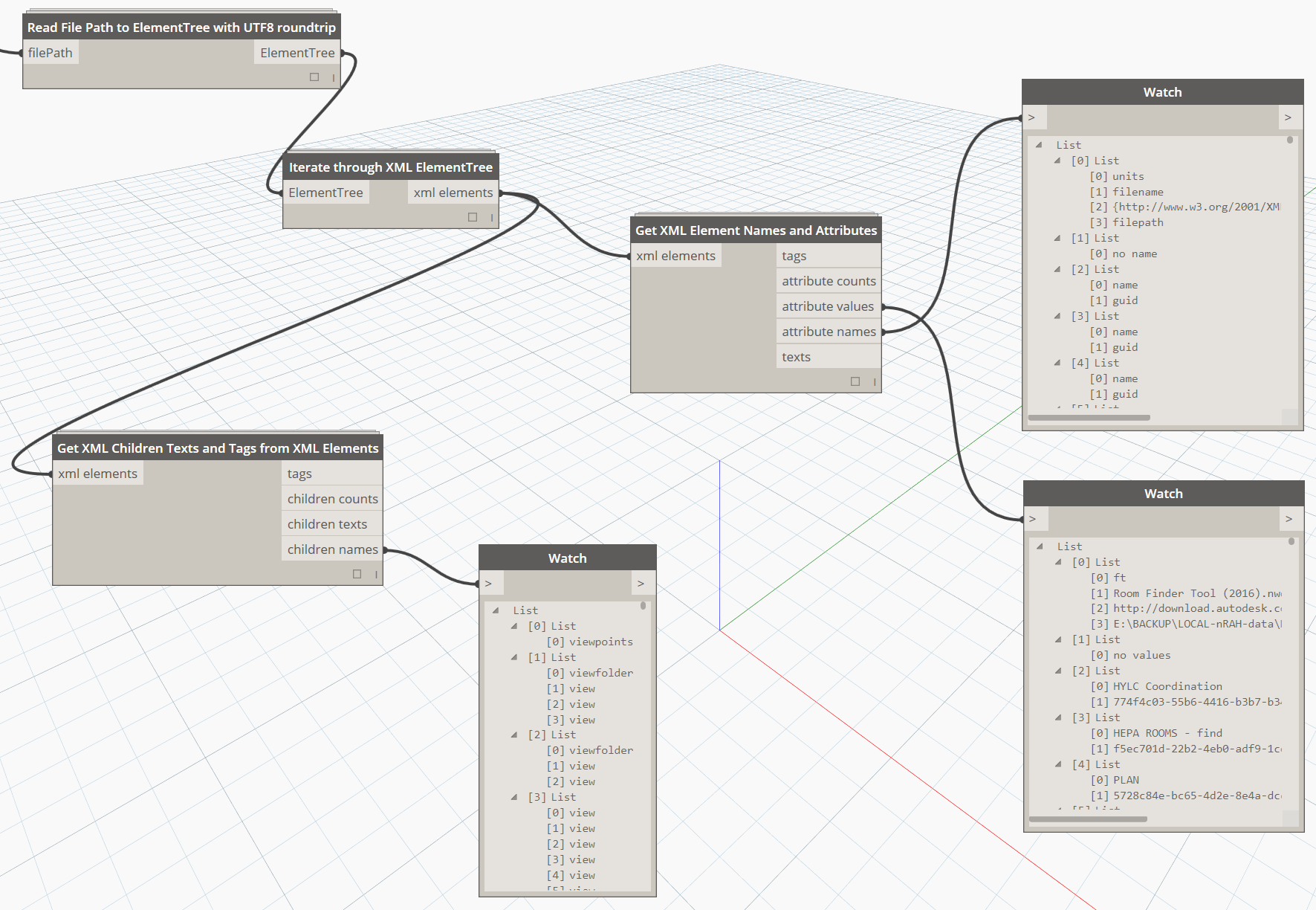
Once we have this ElementTree object in hand, we can start to do some interesting things, like: Iterate through tree to get individual XML elements
andShow a hierarchical representation:
With the individual elements, we can Get Attribute names and values, and the Get the children of those elements:
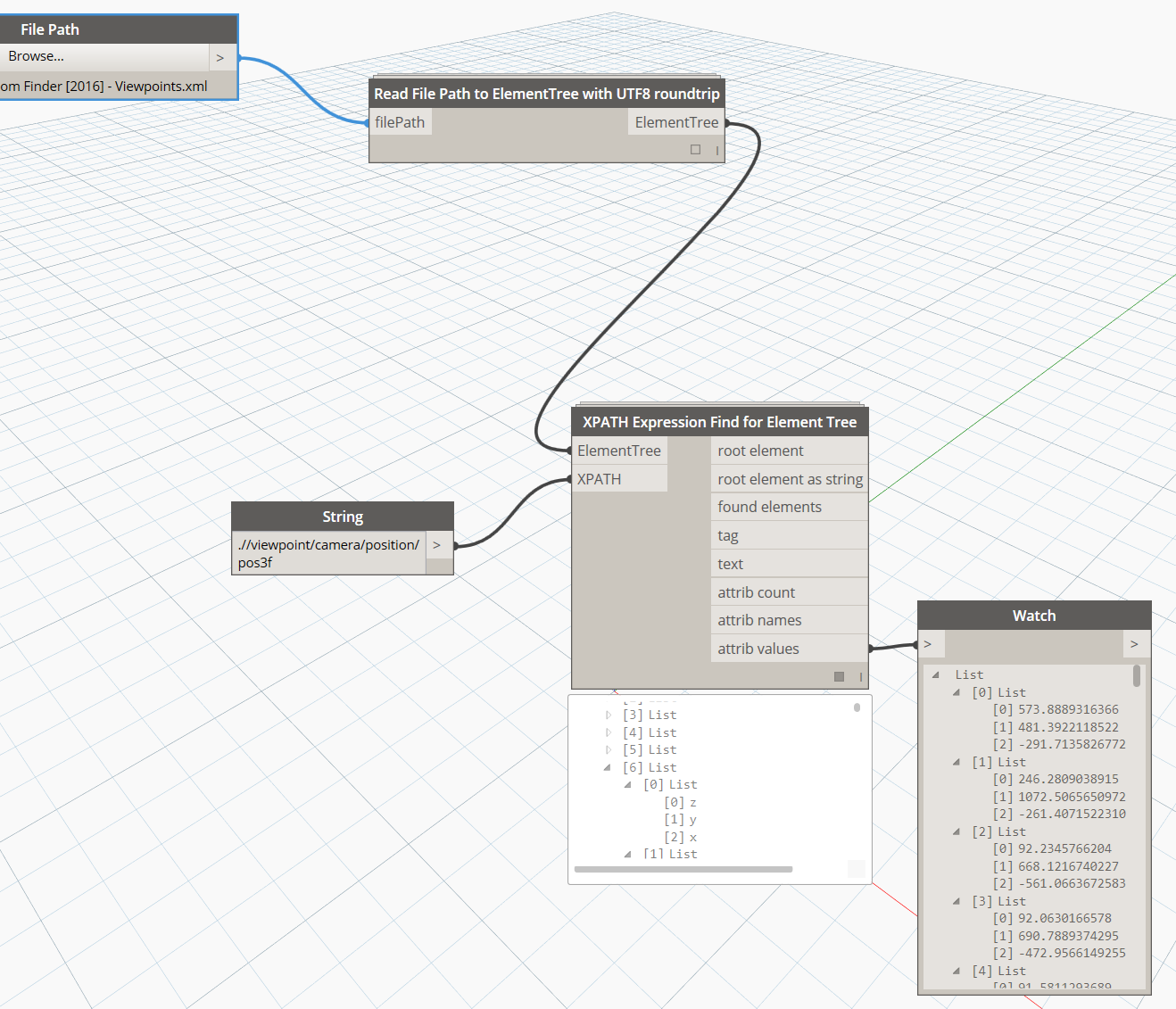
Obviously, you can immediately do some nice lookups against these lists in Dynamo, depending what information you want. However, on large XMLs this can be quite slow. Happily, ElementTree provides some basic XPATH support, which looks a bit like this:
With the XPATH supportand an understanding of the xml hierarchy, I have created a node to do XPATH calls straight to the ElementTree object:
Now that we can ‘snip’ out useful information from the XML, we can do interesting things with it, like make some points:
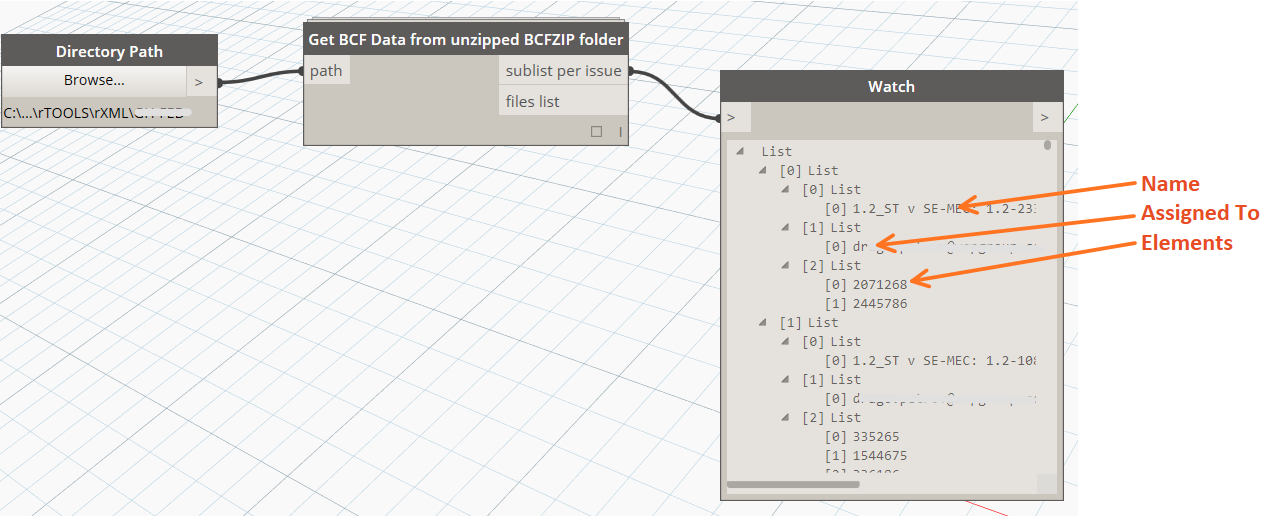
When it comes to BCF, its a little bit more challenging. I haven’t figured out how to unpack the bcfzip directly to memory (yet), so we have do that manual step first. Once we have a ‘folder’ from the BCFZIP, we can get the bcfv files from inside it and then get information from them, like this:
So, in the latest Bakerypackage are the nodes needed toread a variety of XMLfiles, get information from them, and do some useful things with that information. It was a learning experience for me, and I hope its useful to you 🙂